










































Why Data Lineage is Essential for AI: 7 Governance Challenges Solved by AI-Ready Lineage

AI-ready data lineage is a comprehensive, auditable record of how data flows through your organization, designed to support AI governance requirements, including explainability, traceability, and accountability.
When M&T Bank deployed Microsoft Copilot to 16,000 employees, they needed to prove which data their AI accessed, predict what would break if they changed upstream systems, and protect against misuse.1 Traditional lineage tools were unable to answer these questions.
As financial services firms deploy GenAI to thousands of employees, governance teams struggle to trace which data those AI systems accessed last month. Most organizations deploy AI with fragmented lineage that can’t answer basic regulatory questions: “Can you prove this AI decision wasn’t based on unauthorized data?” “Which models will break if you change this data source?” “Who owns the data feeding this high-risk system?”
If your team needs weeks instead of hours to respond, you’re already behind.
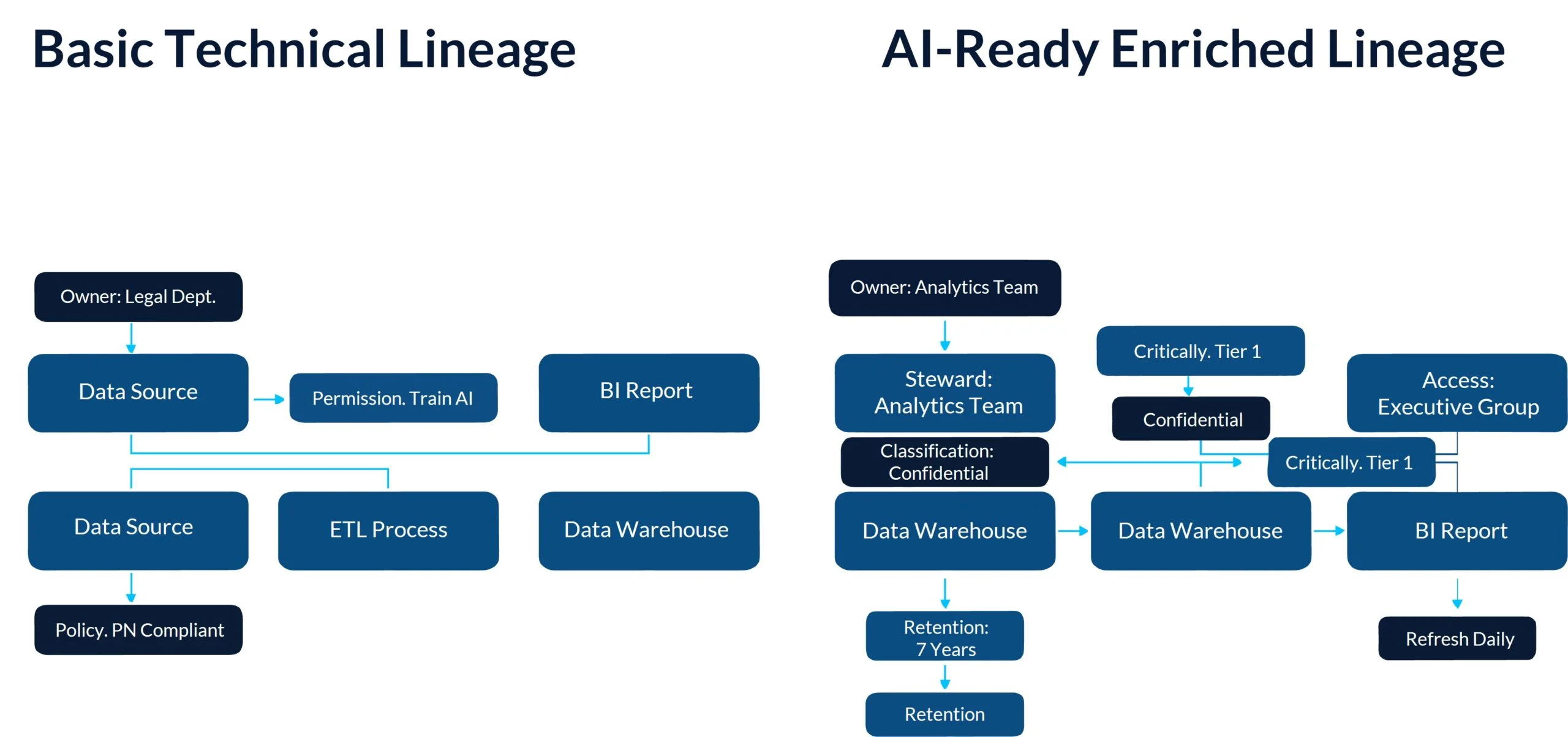
Traditional lineage maps technical connections: which tables feed which processes. AI governance requires four additional capabilities:
| Feature | Traditional Lineage | AI-Ready Lineage |
|---|---|---|
| Focus | Technical metadata | Business context |
| Timeframe | Current state only | Temporal states (historical & future) |
| Audience | IT-focused | Governance-enabled |
According to Tina Chace, VP of Product Management at Solidatus, who implements AI compliance at major banks, “Regardless of whether data feeds a traditional ML model or an AI agent, you still need to document where it comes from, if it’s fit for purpose, and what transformations happen. This takes a minimum of nine months for any AI deployment in a bank.”
U.S. financial institutions follow Model Risk Management (MRM) guidance (SR 11-7), requiring comprehensive documentation before any AI system enters production. This process, covering data sources, transformations, and fitness for purpose, takes a minimum of 9-12 months for approval. The EU AI Act (Regulation 2024/1689), which entered into force in August 2024, adds binding requirements for high-risk AI systems, including explainability and risk management. GenAI doesn’t get exemptions from these frameworks; it faces further scrutiny.
1. Proving data provenance for regulatory compliance
What regulators require: Exact documentation of where AI training data originated, how it was transformed, who validated it, and proof of these facts at any point in time.
The European Central Bank’s BCBS 239 interpretation demands “complete and up-to-date lineage at the data attribute level.” Most catalogs show the current state only and can’t reconstruct historical data states or prove usage permissions.
Bi-temporal lineage capability lets you roll back your entire data estate to any historical moment. When an auditor asks about a disputed March decision, you show them the exact data sources, transformation logic, and quality rules that were in place at the time.
One customer’s result: “Solidatus allowed us to answer regulator questions in hours instead of weeks.” Hours versus weeks is the difference between governance enabling AI deployment and governance blocking it.
2. Preventing silent or avoidable AI failures with change impact analysis
AI models often fail silently, and many of these failures are preventable. An upstream schema change results in a degradation of your fraud detection model, from 94% to 67% accuracy, over three weeks. No errors. No alerts. Just quiet degradation until customer complaints surface.
Royal London Asset Management faced this risk during a massive transformation: a simultaneous migration to BlackRock’s Aladdin platform, along with new cloud architecture, which affected 2,000 tables, 175,000 fields, and 41 systems.
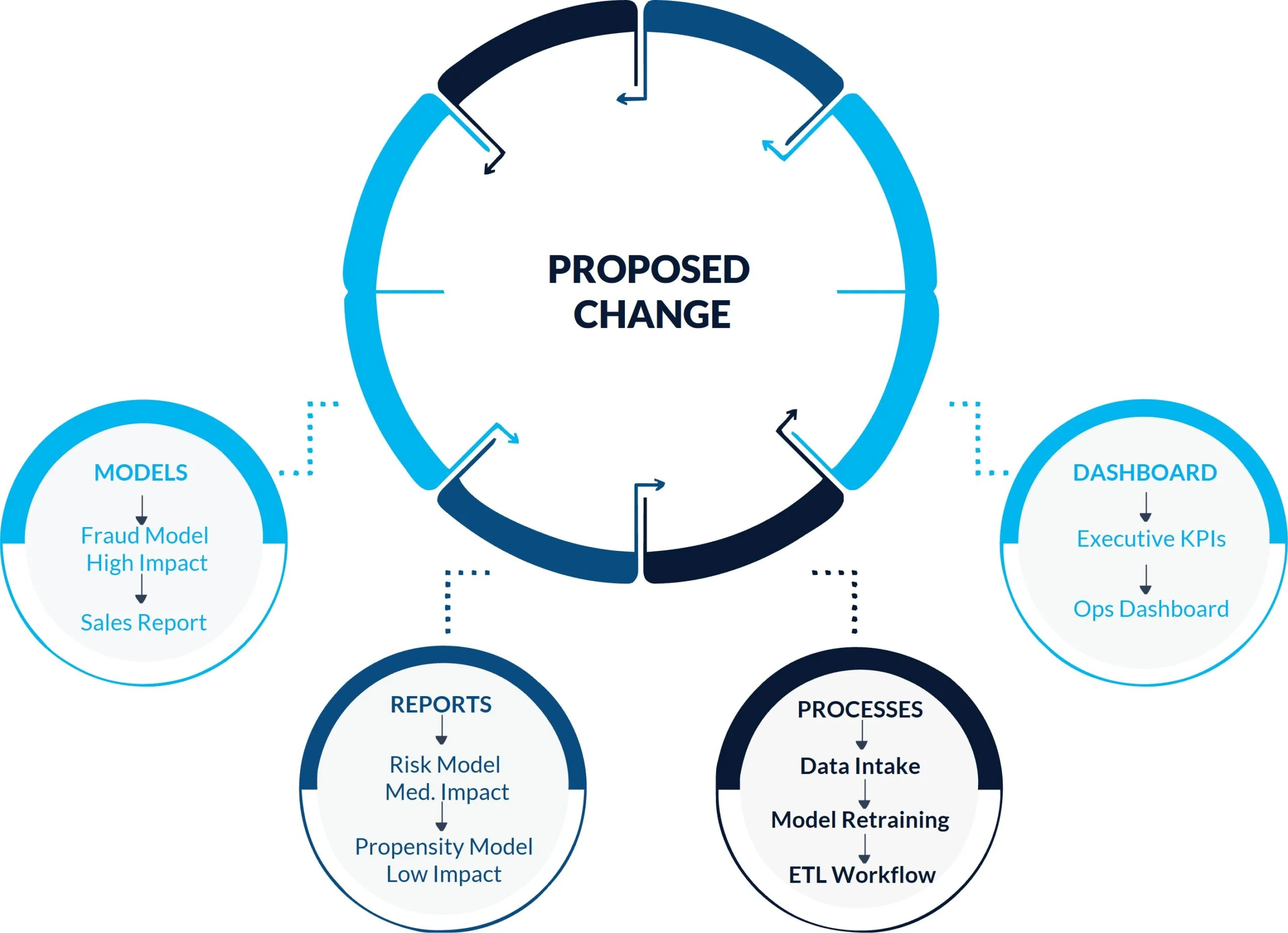
They used bi-temporal branching to model the transformation before introducing it to production, creating parallel versions to test changes and identify potential breaking points first.
Three questions change the impact analysis answers:
You identify failures in planning, not production.
3. Connecting models to accountability and ownership
Most organizations can’t answer: Who owns the data feeding this model? What’s the SLA? Which business process depends on it? What’s the risk classification?
BNY manages nearly $50 trillion in assets. Their Chief Data Officer described the challenge: “Data is key to everything we do. Ensuring proper governance is essential to how we operate.”
What governance with lineage delivers:
BNY’s result: “Complete, end-to-end lineage for three regulatory reports in under four weeks.”
4. Making GenAI prompts and RAG workflows auditable
RAG systems decide at runtime which documents to retrieve. You don’t control each specific retrieval, but rather, the AI agent selects from a predefined corpus based on the prompt.
Consider an AI assistant for relationship managers. It should access product documentation and research. It should never retrieve client trade data, compliance files, or material non-public information.
Three GenAI governance requirements:

5. Tracing AI agent decision chains for explainability
AI agents plan action sequences, not just single responses. An agent assisting with financial analysis might retrieve credit policy documents, analyze them, determine that loan performance data is needed, access hospitality sector indicators, extract historical loss data, and then synthesize recommendations.
Each step involves decisions based on the findings from previous steps. Traditional lineage shows “these sources were accessed.” Agentic lineage captures “the agent decided to access X because it found Y in source Z.”
The EU AI Act and U.S. model risk management require documentation of decision processes. For agents, this means capturing: retrieval decision chains, intermediate reasoning, data sources at each step, and how conclusions influenced subsequent actions.
Tina Chace’s guidance: “For agents, you’re not training the model yourself, but you are flowing data into it, in which case you still need to document document that data flow and its context.”
6. Filtering training data with trust scores
Not all data should be available to AI, especially if it lacks quality controls, carries licensing restrictions, contains biases, PII, or violates regulations.
Trust scoring assigns ratings based on:
Automated filtering prevents violations from occurring. High-trust datasets are available automatically. Medium-trust requires review. Low-trust gets restricted.
For organizations using Microsoft Purview or Collibra, Solidatus provides the business context that these catalogs often lack. Purview says, “This dataset exists.” Solidatus says, “This dataset scores 8/10 provenance, 9/10 quality, is licensed for AI, owned by Marketing with 99.9% SLA, subject to GDPR, approved for propensity models but not credit risk.”
7. Meeting regulatory requirements with audit-ready documentation
The EU AI Act creates binding obligations for high-risk systems. U.S. regulators require documentation before AI enters production. These requirements intensify for AI, not disappear.
What regulators examine:
Chris Skinner, Data Governance Director at LSEG, explained their approach: ensuring “with new products as they go out the door, they meet the standards we’ve now defined, and we build in by design those data governance controls.”
Organizations that demonstrate compliance move faster on AI. They deploy while competitors prepare documentation.
Business context, not just technical connections
Basic lineage shows table A connects to table B. AI governance requires answers to: Who owns this data? What policies govern it? Can we use it for AI training? What business process depends on it? What are the costs and SLA commitments?
Andrew Foster, M&T Bank’s Head of Data: “Some parts can be scanned and automated with quick value. But a lot comes from historic tribal knowledge. You have to find ways to make that sustainable.”
Bi-temporal capability for audit and simulation should look like Ecosystem integration, not silos
Basic lineage shows the current state. AI governance requires time travel.
Looking backward: Roll back to see the exact data state historically. Reconstruct the precise sources, logic, and quality from any moment for audits.
Looking forward: Branch your model to test proposed changes. Identify breaking points in planning, not production.
This transforms lineage from passive documentation into an active simulation engine.
Solidatus serves as Microsoft Purview’s Data Lineage Integration Partner. Microsoft has native lineage but partnered with Solidatus for “advanced” capability. While Purview provides excellent ecosystem integration, complex enterprises often require the dedicated depth and bi-temporal capabilities Solidatus adds
For Collibra users, Solidatus adds lineage depth. Open API architecture ensures vendor-agnostic integration across multi-cloud, hybrid, and on-premise environments.
Can you answer regulator questions in hours instead of weeks?
When auditors request complete lineage documentation, including sources, transformations, quality rules, and owners, how long does assembly take?
Can you simulate the impact before making changes?
When infrastructure proposes migrating a database, can you immediately show which models, reports, and processes depend on it?
Can you recreate data states from six months ago?
When compliance asks about a past AI decision, can you reconstruct the precise data state, transformations, and logic from that time?
Choose priority based on immediate pressure:
Change impact analysis delivers the fastest ROI with active transformation programs. Prevents failures, accelerates approvals, and de-risks initiatives. Payback: 3-6 months through avoided incidents.
AI data provenance addresses regulatory pressure directly. Facing audits, AI Act compliance, or model risk management? This reduces preparation time by 75-90%. Payback: first audit cycle responding in hours.
GenAI prompt lineage enables safe RAG deployment. When governance blocks GenAI programs, this proves you can deploy safely. Payback: immediate program unblocking.
Conduct your gap analysis using the three diagnostic questions. Evaluate current tools against business context, bi-temporal capability, and ecosystem integration. Identify the burning platform that causes the most pain.
Consider hybrid deployment: fast automated value for modern systems combined with curated modeling for complex rules and legacy environments.
You cannot govern what you cannot trace. AI systems making thousands of decisions daily across dozens of sources require more than spreadsheets and tribal knowledge.
Organizations moving fastest on AI have the best governance, not the best models. They deploy quickly because they prove compliance quickly. They answer regulators in hours because they have a complete, auditable lineage. They prevent failures by simulating the impact of changes first.
The question isn’t whether you need AI-ready lineage. It’s whether your current approach delivers it before your next audit, regulatory inquiry, or AI failure that damages customer trust.
For most organizations, the answer is no. That’s the problem you can solve, starting now
1 “Unifying the Enterprise: How M&T Bank Is Rewriting the Rules of Data Governance with Solidatus.” 2025. Solidatus. September 30, 2025. https://www.solidatus.com/resource/unifying-the-enterprise-how-mt-bank-is-rewriting-the-rules-of-data-governance-with-solidatus/
Published on: December 3, 2025

Subscribe for the latest news, blogs, and resources.