










































Proving data lineage to regulators

SR 26-2, the ECB’s May 2024 guide, and what data catalogs miss.
On April 17, 2026, the Federal Reserve, OCC, and FDIC jointly released SR 26-2, the first major update to US model risk management guidance in fifteen years.1 The new tri-agency guidance is principles-based, applies to banking organizations with over $30 billion in total assets, and excludes generative and agentic AI from its scope. Footnote 3 of the attachment adds the twist. Banks are still expected to build their own governance frameworks for those systems based on the principles laid out in the guidance.
SR 26-2 never uses the phrase “data lineage,” yet every principle in it rests on evidence that only granular lineage can produce. The European Central Bank’s May 2024 guide said the same thing in plain language eighteen months earlier, calling for “complete and up-to-date data lineages on data attribute level.”2 Different regulatory styles land on the same evidentiary floor, and catalog-level lineage will not clear it. The rest of this piece walks through the five questions an examiner will ask and the evidence a compliance team needs to produce under exam conditions.
The guidance reads as a high-level framework, yet the data requirements sit in almost every section. Inherent risk (Section III) depends on “the quality of inputs for the model, and data constraints.” Model testing (Section IV) must include a “a critical assessment of data quality, relevance, and inputs.” Validation work (Section V) documents “data selection” as part of conceptual soundness, then monitors “data relevance” over time. Even vendor products fall under the principle, with Section VII requiring evaluation of “data, parameter values, or complete models” supplied by third parties. Each of these assumes an underlying evidence trail.
“Generative AI and agentic AI models are novel and rapidly evolving. As such, they are not within the scope of this guidance.”
— SR 26-2 Attachment, Footnote 3, April 17, 2026
The ECB put it plainly eighteen months earlier. The May 2024 Guide on Effective Risk Data Aggregation and Risk Reporting requires “complete and up-to-date data lineages on data attribute level” as the minimum for an effective data governance framework. The Bank Policy Institute reported “whispers” among modeling teams that examiners had already begun changing data lineage requirements for certain models under SR 11-7.3 SR 26-2 formalizes what the field was already hearing in audit rooms.
Inside the audit room, the abstraction becomes specific. When the Head of Risk Data at a G-SIB faces her first validation review under SR 26-2, the examiner does not ask which system holds the credit portfolio data. She asks how a specific probability-of-default (PD) estimate arrived at the model, and what the lineage looked like six months ago versus today. The examiner expects a path from source to model input, not a dataset label.
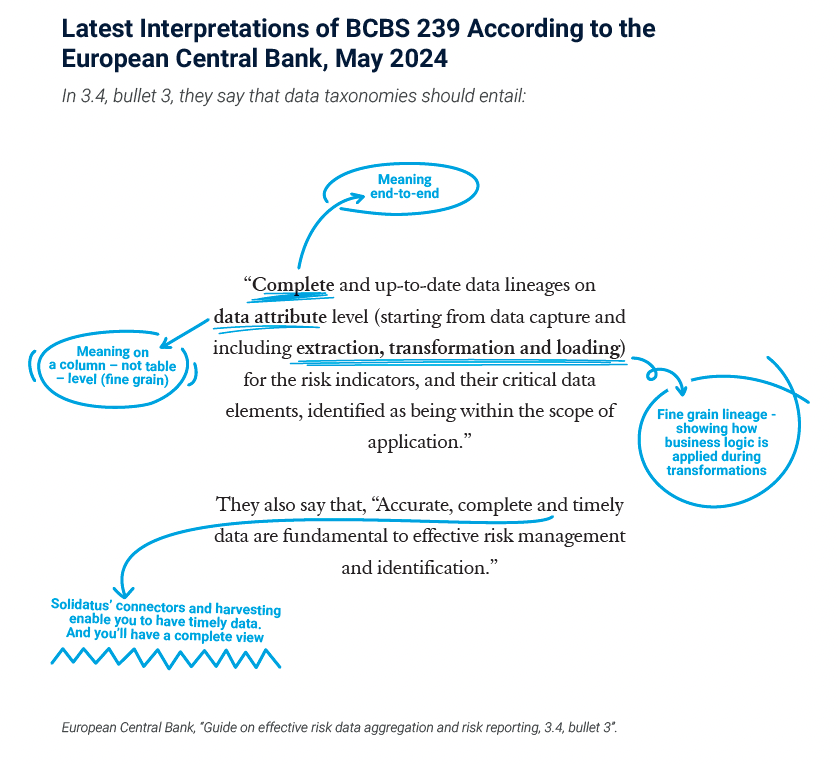
Catalogs answer this question with a source system tag. An examiner applying SR 26-2’s “data selection” requirement needs more than that. She needs the full column-level path from the PD value back to the point of capture, through every staging layer, ETL job, and rating-to-PD mapping that touched it. The ECB guide spells out the standard. Data lineage has to be complete, up-to-date, and “on data attribute level (starting from data capture and including extraction, transformation and loading).”4 A dataset-level answer cannot demonstrate provenance for the single PD figure the examiner just named. That evidence comes from a data lineage platform built around attribute-level provenance, not a catalog built around the dataset.
A catalog records the schema at the time the connector last ran. The transformation logic lives elsewhere, and so does a time stamp on the rules. SR 26-2’s model-testing principle wants “a critical assessment of data quality, relevance, and inputs,” and there’s no way to satisfy that without knowing which rule applied on which date. A PD estimate isn’t produced by one calculation. It passes through rating-scale translations and through-the-cycle adjustments, then regulatory floors and economic-cycle overlays, before reaching the model. Without a rule-level change history, the examiner has nothing to check. The fix is a lineage platform that treats transformation logic as its own object, versioned every time a rule changes.
SR 26-2’s governance section calls for clear roles and responsibilities across the model lifecycle. EU AI Act Article 10 extends that requirement to every high-risk AI system that processes training, validation, or test data.5 Catalogs hold stewardship fields that name a team or a person, yet the examiner’s question goes beyond that. A credible answer pulls three things together for each PD estimate: who owns it, which Internal Ratings-Based (IRB) policy governs the calculation, and which regulatory regime applies. Then it pushes that context upward to every risk-weighted asset (RWA) figure and every Pillar 3 public-risk disclosure downstream. A catalog entry doesn’t reach that far. A lineage layer can, if it carries ownership, policy, and regime on every element, and can traverse to every downstream consumer.
“Ongoing model monitoring involves an evaluation of the extent to which a model is performing as expected given potential changes in products, exposures, activities, clients, data relevance, or market conditions.”
— SR 26-2 Attachment, Section V, April 17, 2026
Take a third-party ratings vendor that moves from a 15-grade to an 18-grade scale. The rating-to-PD mapping table breaks silently, and every downstream consumer inherits the shift. A catalog can list which tables reference the feed, but it can’t simulate what breaks downstream, whether that’s the PD calculation, the RWA figure, or the Pillar 3 disclosure. A lineage-first platform connects the feed all the way through to the disclosure and runs impact analysis before the change hits production.
An examiner does not want today’s map. She wants the map as of the date the model was last validated, so that she can compare the PD inputs at validation against the PD inputs today. Generally, a catalog overwrites the historical state with each scan, and there is no way to reproduce the map on validation day. Bi-temporal lineage, by contrast, restores the full map to any point in time, shows the data as it was, and contrasts it against today. SR 26-2’s “data relevance” monitoring principle depends on exactly that capability, which is the evidence chain a bank needs to defend a model years after it went live.
Data catalogs are purpose-built to index assets, and they do that work well for users who need to search, discover, and classify. Data lineage in most catalogs is a view derived from connector-captured metadata, which means the map is only as complete as the automation behind it. That leaves manual flows, legacy systems without machine-readable schemas, and column-level transformations buried in business rules all outside the map. An examiner has no reason to care about that limitation. She still has to apply SR 26-2’s principles on data quality, data selection, and data relevance, which are not questions a discovery catalog can answer.
Different regulatory styles land on the same architectural floor. The table below maps the five regimes a $30B+ international bank is likely to answer to in 2026, and what each one asks of lineage.
| Regulation | Effective | What it asks of data lineage |
|---|---|---|
| BCBS 2396 | 2013 (G-SIBs) | Risk data aggregation and reporting, reinforced by the ECB 2024 guide |
| ECB Guide on Effective Risk Data Aggregation 7 | May 2024 | Complete, up-to-date, attribute-level data lineage is a minimum requirement |
| DORA8 | January 2025 | ICT risk management that covers traceability for third-party data |
| EU AI Act, Article 109 | 2024–2026 phased | Data governance and traceability for high-risk AI training, validation, and test data |
| SR 26-210 | April 2026 | Principles-based data quality, selection, relevance, and inputs across the model lifecycle |
A bank that builds to the ECB’s attribute-level requirement already clears the SR 26-2 principles-based standard, but the reverse does not hold. A bank optimizing for the SR 26-2 text alone falls short of the ECB’s specificity, and every bank with European operations has to meet both. The real decision for a CDO is which data lineage architecture can satisfy the most specific requirement while remaining defensible under a principles-based review.
The GenAI carve-out amplifies the point. SR 26-2 tells $30B+ US banks to build their own governance for generative and agentic AI without any specification for what that looks like. Article 10 of the EU AI Act is the only prescriptive rulebook either regulator has actually published for training data governance, and it already works at the attribute level. A bank that wants to clear both exams needs column-level lineage that also carries a bi-temporal view.
The five questions map to a concrete set of evidence. A bank that can produce these items clears both regimes:
The fifth item is the one most banks underestimate. SR 26-2 asks for a record of how the state moved, not a static map of today. The record must name the proposed changes, the ones the team approved, and when each landed. Solidatus’s AI Lineage Assistant was built for that job. Every AI-proposed lineage change gets logged with a reviewer, and the record survives the next audit. The ECB put the same expectation at the attribute level back in May 2024, and SR 26-2 §VI brings it into US banks.
Any missing item on the checklist turns into a finding waiting to happen at the next exam. Benchmark your readiness against the full Solidatus BCBS 239 whitepaper.
1Board of Governors of the Federal Reserve System, Federal Deposit Insurance Corporation, and Office of the Comptroller of the Currency. “Supervisory uidance on Model Risk Management.” SR Letter 26-2 Attachment. April 17, 2026.
https://www.federalreserve.gov/supervisionreg/srletters/SR2602a1.pdf.
2European Central Bank Banking Supervision. Guide on Effective Risk Data Aggregation and Risk Reporting. May 2024.
https://www.bankingsupervision.europa.eu/ecb/pub/pdf/ssm.supervisory_guides240503_riskreporting.en.pdf.
3Bank Policy Institute. “The Most Damaging ‘Guidance’ in Banking.” 2025. https://bpi.com/the-most-damaging-guidance-in-banking/.
4European Central Bank Banking Supervision. Guide on Effective Risk Data Aggregation and Risk Reporting. May 2024. https://www.bankingsupervision.europa.eu/ecb/pub/pdf/ssm.supervisory_g,uides240503_riskreporting.en.pdf.
5European Union. Regulation (EU) 2024/1689 of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act). Article 10. 2024. https://eur-lex.europa.eu/eli/reg/2024/1689/oj.
6Bank for International Settlements, Basel Committee on Banking Supervision. “Principles for Effective Risk Data Aggregation and Risk Reporting” (BCBS 239). January 2013. https://www.bis.org/publ/bcbs239.pdf.
7European Central Bank Banking Supervision. Guide on Effective Risk Data Aggregation and Risk Reporting. May 2024.
https://www.bankingsupervision.europa.eu/ecb/pub/pdf/ssm.supervisory_guides240503_riskreporting.en.pdf.
8European Union. Regulation (EU) 2022/2554 on Digital Operational Resilience for the Financial Sector (DORA). Effective January 17, 2025. https://eur-lex.europa.eu/eli/reg/2022/2554/oj.
9European Union. Regulation (EU) 2024/1689 of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act). Article 10. 2024. https://eur-lex.europa.eu/eli/reg/2024/1689/oj.
10Board of Governors of the Federal Reserve System, Federal Deposit Insurance Corporation, and Office of the Comptroller of the Currency. “Supervisory Guidance on Model Risk Management.” SR Letter 26-2 Attachment. April 17, 2026. https://www.federalreserve.gov/supervisionreg/srletters/SR2602a1.pdf.
01.
SR 26-2 never uses the phrase “data lineage,” yet its principles-based requirements for model risk management cannot be met without it. Section III ties inherent risk to “the quality of inputs for the model, and data constraints.” Section IV requires testing to include “a critical assessment of data quality, relevance, and inputs.” Section V requires validation to document “data selection” and monitor “data relevance.” Producing evidence for each of those principles requires column-level, time-stamped data lineage. The guidance is non-enforceable, but examiners apply the principles as their evaluation lens.
02.
The European Central Bank’s Guide on Effective Risk Data Aggregation and Risk Reporting, published in May 2024, specifies “complete and up-to-date data lineages on data attribute level (starting from data capture and including extraction, transformation, and loading)” as a minimum requirement of an effective data governance framework. Attribute level means column level — not dataset level. The guide applies to Eurozone banks under ECB supervision and reinforces the BCBS 239 principles published in 2013.
03.
SR 26-2, issued April 17, 2026, by the Federal Reserve, OCC, and FDIC, supersedes SR 11-7 (2011) and SR 21-8 (2021). It retains the fundamental framework covering model development, validation, governance, and vendor oversight, but introduces a risk-based, materiality-tailored approach. Generative AI and agentic AI are explicitly carved out of scope under Footnote 3, with banks expected to build their own governance frameworks based on the guidance’s principles.
04.
No. Data catalogs are purpose-built to index assets for search, discovery, and classification. The lineage a catalog produces is a view derived from connector-captured metadata, which means the map ends where the connectors end. Manual flows, legacy systems without machine-readable schemas, column-level transformations inside business rules, and historical state all sit outside catalog coverage. Regulatory lineage evidence requires a purpose-built data lineage layer that models transformation logic as a first-class object and supports bi-temporal restoration.
05.
Attribute-level lineage traces a single column (for example, a probability-of-default value) from the point of data capture through every staging layer, ETL job, calculated field, transformation rule, and business override, to the exact attribute that feeds a model or report. Dataset-level lineage stops at the table or dataset object, which cannot answer provenance questions about a single value inside that dataset. The ECB’s May 2024 guide explicitly requires attribute-level coverage.
06.
Produce five pieces of evidence: end-to-end column-level lineage from source to model input; transformation logic modeled as a first-class, time-stamped object; bi-temporal snapshots that restore any historical state; impact analysis from any data element to every downstream consumer; and a governed change record tracking recommendations, responses, and exceptions across the model lifecycle. Banks that can present this set meet both the SR 26-2 principles lens and the ECB’s attribute-level requirement.
Published on: June 9, 2026

Pre-change impact analysis for data estates that feed AI

What BCBS 239 and SR 26-2 now demand at the column level

How LSEG turned data lineage into a strategic asset for AI trust

Five data lineage myths that the masterclass got right

In May 2024, the ECB released its ‘Guide on effective risk data aggregation and risk reporting (RDARR)’...

How data lineage supports compliance with key data-related regulations

Read why advanced data lineage is crucial for business success
An update on some recent developments in our latest product releases
Read more about data lineage and its business impact, including on AI, BCBS 239 and more
Navigate BCBS 239’s rigorous standards with advanced data lineage

Solidatus data lineage partners with Microsoft Purview to help enterprises trust their data

Read about the new Solidatus interface

Read our key takeaways from Gartner D&A Summit 2024

Video introducing our new interface and core features like Connected Catalog and Data Map

Read about Solidatus and Snowflake Horizon's governance solution

Explore the various aspects of data lineage and its crucial role in your organization.

Basel III is changing – are you prepared? Read 3 easy steps with Solidatus
Read how we helped successfully launched the Houston Women in Data Chapter

Exploring the parallels between urban planning and data planning projects

71% of senior data leaders in financial services polled are close to quitting their jobs

Take a look at what's new in our partnership with Snowflake

VP Product, Tina Chace, reflects on the Gartner conference, covering data governance and AI

We’ve linked the Eurovision Song Contest to the realm of data governance and data lineage

In the latest Gartner® research note, find out what active metadata is

The role of metadata, dynamic visualization and inference across metadata

Automatic connectors are essential for efficiently mapping metadata but not all are created equal. We look at the most important...

With news that Solidatus and Corlytics are joining forces to ease the burden of tracking data regulations, we look at...

We discuss injecting active metadata into your governance and 4 other things we’re looking forward to at the Gartner® Data...

Subscribe for the latest news, blogs, and resources.